
Unleashing causal machine learning to enhance decision-making
In the world of machine learning, accurate forecasts often form the backbone of decision-making. However, in an environment where context and actions constantly evolve, the robustness of predictive models may be compromised over time.
For a more comprehensive strategy, it is advisable to explore the realm of Causal Machine Learning. This state-of-the-art approach empowers us to unveil cause-and-effect relationships and achieve precise results to anticipate the outcome of specific actions.
Understanding Causal Machine Learning
Traditional Machine Learning primarily focuses on identifying correlations and making predictions based on these correlations.
Causal Machine Learning takes a step further by striving to comprehend the cause-and-effect connections between variables. In Causal ML, the objective is not only to determine the features that contribute to predicting an outcome but also to uncover the causal factors that induce the outcome and accurately quantify their impact.
—
Consider, for instance, the task of predicting customer churn. Assume we work for a telecom operator for which we create a comprehensive dataset that will enable us to accurately predict customer churn for each customer.
After training an ML model and conducting rigorous testing, it became evident that the price of the subscription emerged as the most influential feature. Upon presenting our results, business stakeholders made the logical decision to grant a discount to the clients identified as "at risk". Doing so, they were able to retain most of the clients.
Later, when the model asked again to predict churn levels, the client will receive a result indicating that there are zero clients currently at risk. This result does not make a lot of sense from a business perspective.
By granting a discount to retain customers, the operator disrupted the relationship between price and customer loss, providing a compelling reason for their decision.
—
The concept to keep in mind when developing a prediction model is that the feature with the highest importance score:
May not the best feature to act on (what if the best feature was the age of customer?)
May not even affect the outcome at all.
The latter remark might cause some surprise. However, it is well known that correlation patterns can be spurious.

Focusing solely on predictions is acceptable, but it becomes problematic when decisions are made based on those predictions, particularly when those decisions can directly affect the present state of the environment. Causal ML shifts its attention from mere predictive models that depend on correlations to models that can power the machinery of cause and effect.

Source: XKCD
Turning to Causal Machine Learning
Now is the perfect moment to provide a precise definition for Causal Machine Learning. Causal ML represents a shift in focus from a modeling perspective:
Instead of making predictions, we strive to identify the variables that are responsible for the outcome.
Estimate how that outcome would change if we changed those variables.
Or, in a more formal way: A treatment T causes an outcome Y if and only if changing T leads to a change of Y while everything else is kept constant.
When looking at this change from a business point of view, the evaluation is essentially about answering the question of "what if?". What if I did not change the price I offered to the customer? How many would have churn? This is what is commonly known as a counterfactual. Imagine it as a parallel dimension, where everything remains unchanged except for the way things are handled.
Simulating a parallel universe is undeniably challenging, as is predicting the counterfactual. We never observe this universe, and there might be various causal structures that can fit your problem. This means various treatments to take into consideration. So, how to do it?
Applying Causal ML
Causal Machine Learning shines when coupled with a deep business understanding and a solid foundation in logical reasoning.
The first step is modeling, wherein we construct a causal graph encompassing the treatment, the outcome, and the potential confounding variables. This is where you want to involve the business stakeholders as much as possible, as their insights are going to be extremely valuable. For example, for the churn example above, the Direct Acyclic Graph might look like this:
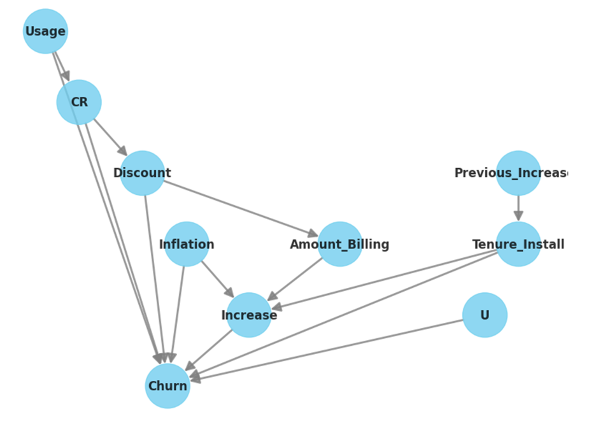
The next crucial step is identification, where you carefully choose the algorithm that will effectively address your specific scenario. This could involve a range of options, such as randomized experiments, thorough consideration of any confounding factors, or conducting rigorous A/B testing. Microsoft's Causal ML offers a decision tree to help choose the right library for your context.
After modelling and identification, the third step is to run the estimation, employing the selected algorithm on your dataset.
The conclusive step is refutation where one tests the validity of the model. This could be in the form of a placebo test, where the treatment is replaced by a random value to see if there is any effect on the outcome.
The thorny issue of A/B testing
Experiments run by Microsoft's team illustrate the plethora of applications for Causal Machine Learning. They include scenarios such as studying hotel booking cancellations, analyzing the effectiveness of customer loyalty programs, or even predicting customer churn.
At this point in the article, readers might consider: “We are already implementing causal machine learning. I ran A/B testing recently.”
While A/B testing is an important element of Causal ML, it must be approached with great care, especially in a business context.
The success of A/B testing relies heavily on essential assumptions, one of which is to carry out only one experiment at a time. In addition, A/B testing does not allow you to discriminate a priori your customers.
Let’s take a new example. Imagine you own two sushis places. Those restaurants are similar from every point of view. Size, food, prices, customers segmentation…
Feeling weary of sushis one day, you find yourself longing for a fresh culinary adventure. It is then that you make a bold choice to introduce an entirely new and tantalizing dish.
However, you find yourself torn between the choices of salads and pasta.
You decide to run an A/B testing, and to serve only salads in restaurant 1, and pasta in restaurant 2.
After analyzing the revenue data for a month, it becomes abundantly clear that pasta is undoubtedly the most profitable option! Both of our restaurants specialize in serving a wide variety of delicious pasta dishes. This option might not meet the expectations of all your customers.
Target: Those customers delight in devouring plates of spaghetti but swiftly depart from any restaurant that exclusively serves salad.
Sure Thing: No matter what you cook, these customers will come to your restaurant.
Lost Causes: No matter what you offer on the menu, these customers will never dine at your restaurant.
Sleepy Dogs: If you stop serving sushi, these customers will leave.

In a perfect world, you would be able to exclusively focus on your target customers.
Unfortunately, no one can be treated and untreated at the same time. Only one of these potential outcomes can ever be observed. The unobserved one is a counterfactual. Lack of causal inference can lead to an unexpected loss of customers, which could exceed your expectations.
Why Causal Machine Learning Matters
Causal Machine Learning provides insights that cannot be derived from mere predictions. By being aware of cause-and-effect relationships, a business can make better-informed decisions, and consequently, create robust strategies that remain relevant despite the rapidly changing environment.
While the process might look demanding, the rewards are commensurate, ranging from Nobel Prizes for researchers, to practical business benefits. Once you get the hang of it, Causal Machine Learning has the potential to usher in an era of augmented decision-making powered by informed insights.