
Tech Talk: Is ETL in the cloud possible without coding? (Part 1)
Images: https://www.agilytic.be/blog/tech-talk-etl-cloud-coding-part-1
There is a buildup towards moving all data solutions from on-premise into the cloud. One salient argument could be the possibility of diminishing the Total Cost of Ownership. In this 3-part series of Tech Talks on ETL, we focus on the capabilities of the data tools provided by two leading cloud players - Amazon Web Services (AWS) and Azure.
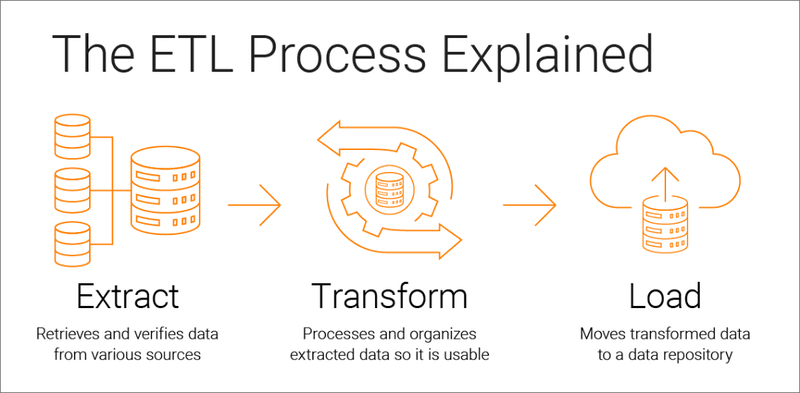
The fundamental question: what is ETL?
ETL represents a typical data movement pattern and stands for Extract (from a source), Transform (the extracted data), and Load (the transformed data, typically into a database, CSV, excel sheets, or a data lake). You usually also save the extracted data in cloud storage (S3 or blobs). So, the name of this process should be probably ELT, or even ELTL, because you load (or save if you will) the data at least twice.
ETL and coding in the cloud
If you are here for a quick answer to the question posed in the title: No, ETL in the cloud doesn't exist without coding, outside of a few simple scenarios that you would typically ignore.
Let me elaborate on this. In ETL, you don’t extract two tables from one source, join them and load the resulting one table into the database of your preferred vendor. Instead, you deal with tens or hundreds of tables from various sources. Then, you have to create complex calculated fields/columns. Finally, you must load the results in different modes like overwrite, append, etc. That means there will (almost) always be more combinations of operations than those foreseen by the cloud vendors and provided for you out-of-the-box.
Scenarios you may face: code or no code?
Since we have three stages of the process, there are three possible sources of limitations and various questions to answer:
Extract. Is there a connector to this data source? Can we extract in bulk? Scan not only tables but also views and materialized views? Save it into parquet?
Transform. What kind of transformations and aggregations are needed? Can we easily debug and preview the data in the development phase?
Load. Is there a connector to desired data sink? What formats are accepted? Can we load in bulks? Can we choose the mode of loading?
If the answer is no to any of these, you will have to customize the process by writing some code. To start, if you look at the popular cloud tools like Azure Data Factory and AWS Glue, you will find some basic templates for simple scenarios. In other words, there are some UI tools given, but coding is probably still 80% of every ETL project. The most popular ETL programming languages are Python, Scala, and SQL.
ETL Tech Talks up next
In Parts 2 and 3, we will describe two cases in which we used Azure Data Factory and AWS Glue to help customers establish their ETL flows and data warehouses.